데이터는 공개는 할 수 없지만 방식은 비슷할 겁니다. kt ip데이터를 받아와서 한 방식입니다.
# def IQR_fun(df,col_1 = 'Server_sum', col_2 = 'Ss_Established'):
def IQR_fun(df,col_1 = 'Server_sum'):
# IQR 구하기
Q3 = df[col_1].quantile(0.75)
Q1 = df[col_1].quantile(0.25)
IQR = Q3 - Q1
IQR_Q3 = Q3 + IQR * 1.5
IQR_Q1 = Q1 - IQR * 1.5
df['target'] = 1
df['target'].loc[((IQR_Q1 < df[col_1]) & (IQR_Q3 > df[col_1]))] = 0 # 이상치 데이터 IQR을 이용한
# Q3 = df[col_2].quantile(0.75)
# Q1 = df[col_2].quantile(0.25)
# IQR = Q3 - Q1
# IQR_Q3 = Q3 + IQR * 1.5
# IQR_Q1 = Q1 - IQR * 1.5
# df['target'].loc[((IQR_Q1 > df[col_2]) | (IQR_Q3 < df[col_2]))] = 1 # 이상치 데이터 IQR을 이용한
return df
data = pd.read_csv('data/IP/DHCP.csv')
# print(f'전체 데이터 세트. \n{data}\n')
# TODO: 예시코드 실행을 위한 Train_set/Test_set 분할입니다. 반드시 이 형태로 학습/테스트할 필요는 없습니다.
idx_half = data.index[data['Timestamp'] == '20210630_2350-0000'].tolist()[0]
data['Timestamp_2'] = [data['Timestamp'][i][0:4]+"-"+data['Timestamp'][i][4:6]+"-"+data['Timestamp'][i][6:8]+" "+data['Timestamp'][i][9:11]+":"+data['Timestamp'][i][11:13] for i in range(len(data))] #형식변환을 위해
data['Timestamp_2'] = pd.to_datetime(data['Timestamp_2'], format='%Y-%m-%d %H:%M', errors='raise')
del data['Timestamp']
data = data.set_index('Timestamp_2',drop=False)
data["Server_sum"] = data['Svr_detect'] + data['Svr_connect'] + data['Ss_request'] #서버부 이상 판단
data = data.fillna(method='ffill') # @@ 0을 넣어보기도 해야할듯
data = IQR_fun(data, 'Server_sum') # IQR을 기법을 이용해 통계적으로 접근한다 #맞는항은 다 0위는 간단한 데이터 전처리를 해준부분 이구요 IQR지표를 활용해서 데이터가 이상치는 target행에 이상치라고 간주하여 0 데이터를 할당하여 이상치를 간주하는 부분입니다.
먼저 가공없이 데이터를 탐색해보면
sns.lineplot(x=data2.index, y='Server_sum', legend='full', data=data2)
서버부 쪽에서는 툭툭 튀는 데이터가 있군요
sns.lineplot(x=data2.index, y='Ss_Established', legend='full', data=data2)
Established 컬럼에서도 툭툭 튀는 데이터가 있는것으로 시각적으로 볼 수 있겠습니다.
# 요일 추세
sns.boxplot(x=data2.dayofweek, y='Server_sum', data =data2)
요일별로 서버부를 상자그림으로 확인했는데 툭툭 튀는 데이터가 매우 커서 상자가 찌부되서 보일정도로 이상한 데이터들이 껴잇음을 확인 할 수 있었습니다.
# 요일 추세
sns.boxplot(x=data2.dayofweek, y='Ss_Established', data =data2)
마찬가지로 Established 컬럼을 요일별로 확인 해본 결과 어느정도 차이가 있음을 확인 할 수 있었습니다.
다음은 시계열 분해를 해보아서 잔차를 판단 해볼것입니다. statsmodels.tsa.seasonal 패키지를 사용하면 편하게 분해가 가능합니다. 해당 컬럼명만 seasonal_decompose에 두고 기간(period = n )만 바꾸어 주면서 적당히 계절성만 보이면 될것 같습니다.
from statsmodels.tsa.seasonal import seasonal_decompose
Server_sum = seasonal_decompose(data2['Server_sum'], model = 'additive' ,period = 365)
fig = plt.figure()
fig = Server_sum.plot()
fig.set_size_inches(15,12)
이렇게 시계열 분해를 하면 잔차가 큰 것들이 보입니다. 해당 부분을 이상치로 판단하였습니다.
Server_sum = seasonal_decompose(data['Server_sum'], model = 'additive' ,period = 1000, extrapolate_trend = 1)
fig = plt.figure()
fig = Server_sum.plot()
fig.set_size_inches(15,12)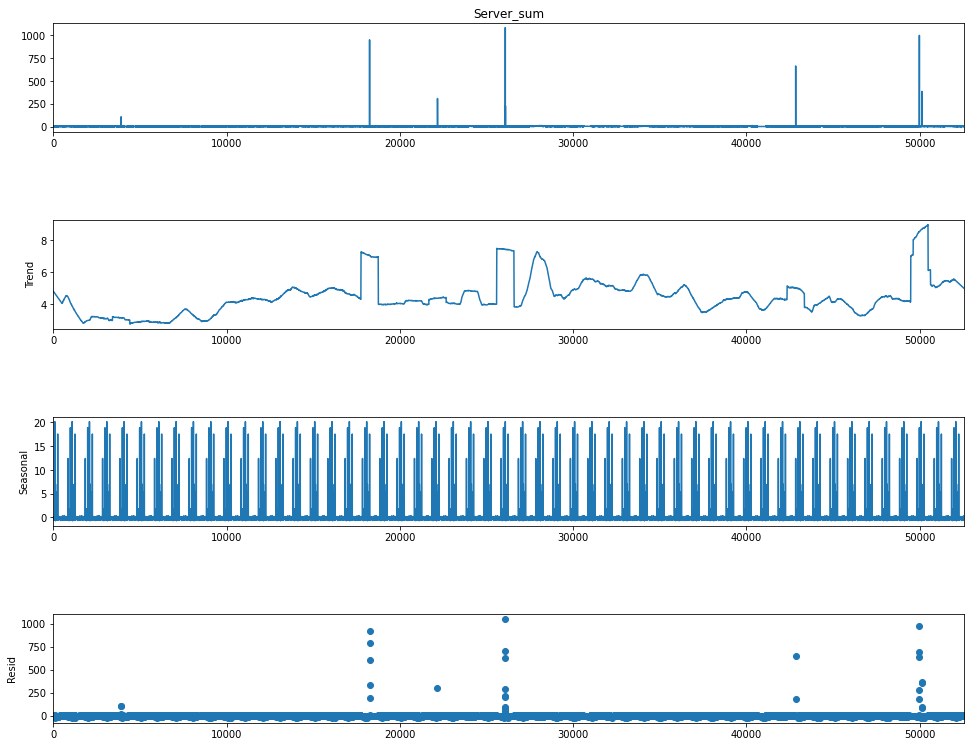
마찬가지로 다른 행도 시계열 분해하여 잔차를 도출해냅니다.
data['Server_sum_trend'] = Server_sum.trend
data['Server_sum_seasonal'] = Server_sum.seasonal
data['Server_sum_resid'] = Server_sum.resid
data['Ss_Established_trend'] = Ss_Established.trend
data['Ss_Established_seasonal'] = Ss_Established.seasonal
data['Ss_Established_resid'] = Ss_Established.resid또한 이런식으로 전부 새 컬럼에 데이터들을 저장해주고 (계절성을 자동으로 분해해주는 statsmodels.tsa.seasonal 패키지의 seasonal_decompose 패키지를 사용하고 plt 까지 그려야 데이터들이 제대로 받아집니다.=> (코드 그대로 따라하면 문제 없음) 그렇게 하지 않으면 na값을 주더라구요 코드오륜줄 알고 한참 고생했습니다.)
data['target'] = 0
data['target'].value_counts()
data['target'].loc[data['Ss_Established']> 400] = 1 # 38
# data['target'].loc[data['Ss_Established_trend']> 30] = 1 #989
data['target'].loc[(data['Ss_Established_resid']> 100) | (data['Ss_Established_resid']< -20)] = 1 # 633개
data['target'].loc[data['Server_sum']> 20] = 1 #30
# data['target'].loc[data['Server_sum_trend']> 8] = 1 # 300 조금만 올려도 0
data['target'].loc[(data['Server_sum_resid']> 100) |( data['Server_sum_resid']< -20)] = 1 #70그리고 눈으로 판단 한 이후에 이 정도 수치를 주고 값을 제출하니
test_set = data['target'][idx_half+1:]
df = pd.DataFrame()
df['Prediction'] = test_set
df['Prediction'].to_csv("ARIMA_pred.csv",index = False, encoding = "cp949")
df.value_counts()
오류 데이터는 135개밖에 안나왔는데 f1스코어는 69점 정도 되더라구요 생각보다 오류 데이터가 많이 없어서 찾는데 고생했었습니다.
'IT - 코딩 > AI, 예측모델' 카테고리의 다른 글
| 자연어처리 긍부정 판단 with python & pytorch (bert) (2) | 2022.11.19 |
|---|---|
| 딥러닝을 응용한 환율예측으로 가상화폐 차익거래 기회 백테스팅 (2) 수익율 측정 (2) | 2022.09.08 |
| 딥러닝을 응용한 환율예측으로 가상화폐 차익거래 기회 백테스팅 (1) (1) | 2022.09.08 |
| DNN을 이용한 분류모델 (with python) (1) | 2022.08.21 |
| 이미지를 이용한 주가예측 (분류) (CNN) 1원장자 (5) | 2022.05.16 |



