import yfinance
import numpy as np
import pandas as pd
import pandas_datareader.data as web
import datetime
import matplotlib.pyplot as plt
import mpl_finance
import math
import seaborn as sns
# import set_matplotlib_hangul
%matplotlib inline
import tensorflow as tf
import os
import PIL
import shutil
df = yfinance.download('AAPL','2000-1-1','2020-1-1')
# df = df.drop(['Volume'],1).drop(['Adj Close'],1)먼저 시가, 고가, 저가, 종가가 있는 아무 주가 데이터를 가져옵니다
a = math.floor(len(df)*0.1)
b = math.floor(len(df)*0.2)
train_all = df[:-a]
test_all = df[-a:]
validation_all = df[-b:-a]저는 일단 학습할데이터, 검증용 데이터, 테스트할 데이터를 따로 나누었습니다. 분류를 위해서 아래 방식 처럼 미리 파이썬 파일이 있는 경로에 cnn.zip파일을 압축해제 해두세요.
def save_png(df,train_test,WINDOW_SIZE):
a2 = int(len(df) - WINDOW_SIZE - 1)
# for i in range(a1):
# df1 = df[0 + 30 * i : 30 + 30*i]
# fig = plt.figure(figsize=(12, 8))
# ax = fig.add_subplot(111)
# mpl_finance.candlestick2_ohlc(ax, df1['Open'], df1['High'], df1['Low'], df1['Close'], width=0.5, colorup='r', colordown='b')
# # plt.show()
# plt.savefig('C:\\Users\\Happy\\Desktop\\help\\cnndata\\cnndata'+str(i)+'.png')
for i in range(a2):
df1 = df[0 + i : WINDOW_SIZE + i]
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
mpl_finance.candlestick2_ohlc(ax, df1['Open'], df1['High'], df1['Low'], df1['Close'], width=0.5, colorup='r', colordown='b')
#plt.show()
df2 = df[(WINDOW_SIZE - 1) + i : (WINDOW_SIZE +1) + i]
df2.reset_index(drop = True)
#오르면 O
if (df2['Close'][0] < df2['Open'][1]):# 종가가 시가 보다 크면
# if (df2['Close'][0] < df2['Close'][1]): # 종가가 다음날 종가보다 크면
plt.savefig('C:\\Users\\Happy\\Desktop\\help\\'+train_test+'\\'+train_test+'O\\cnndata'+str(i)+'.png')
# plt.savefig('C:\\Users\\Happy\\Desktop\\help\\cnnalldata\\cnndata'+str(i)+'.png')
else:
plt.savefig('C:\\Users\\Happy\\Desktop\\help\\'+train_test+'\\'+train_test+'X\\cnndata'+str(i)+'.png')
# plt.savefig('C:\\Users\\Happy\\Desktop\\help\\cnnalldata\\cnndata'+str(i)+'.png')그리고 시고저종이 있는 데이터 프레임을 해당 함수에 집어넣으면,
오늘 종가가 다음날 시가보다 작을 경우 O 폴더에 이미지를 저장하고, 아닐경우 x폴더에 이미지를 저장합니다.(if 문 아래의 주석을 대신 사용할 경우 다음날 종가를 예측하게 됩니다.)
WINDOW_SIZE=30
save_png(train_all,'train',WINDOW_SIZE)
# 아래 두갠 학습 x
save_png(test_all,'test',WINDOW_SIZE)
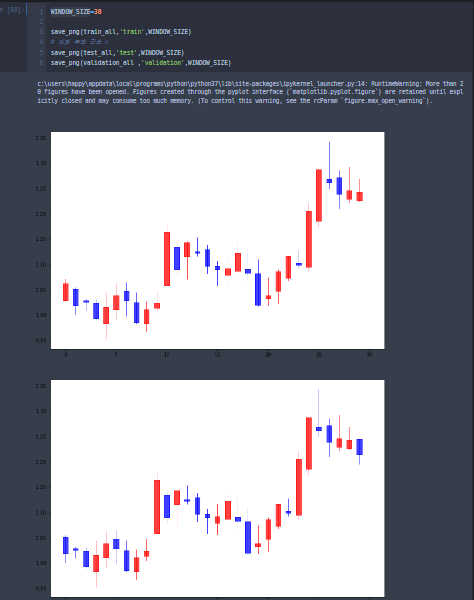
save_png(validation_all ,'validation',WINDOW_SIZE)WINDOW_SIZE 로 얼만큼의 플롯을 이어 붙여서 다음날 시가를 예측할 것인지 정해줍니다. 저는 일봉데이터를 가져왔고 30을 썻으니 거의 1달전 데이터를 가지고 만든 이미지로 다음날 시가를 예측합니다.
# 기본 경로
base_dir = 'C:\\Users\\Happy\\Desktop\\help'
validation_dir = os.path.join(base_dir+'\\validation')
train_dir = os.path.join(base_dir+'\\train')
test_dir = os.path.join(base_dir+'\\test')
# 훈련용 O/X 이미지 경로
train_o_dir = os.path.join(train_dir+ '\\trainO')
train_x_dir = os.path.join(train_dir+ '\\trainX')
print(train_o_dir, train_x_dir)
# 테스트용 O/X 이미지 경로
test_o_dir = os.path.join(test_dir+ '\\testO')
test_x_dir = os.path.join(test_dir+ '\\testX')
print(test_o_dir, test_x_dir)
# 검증용 O/X 이미지 경로
validation_o_dir = os.path.join(validation_dir+'\\validationO')
validation_x_dir = os.path.join(validation_dir+'\\validationX')
print(validation_o_dir, validation_x_dir)두번째 줄의 base_dir의 경로를 아까 cnn zip을 푼 상위 폴더 경로로 입력해줍니다.
그다음으로 이미지 데이터들을 학습에 알맞게 처리해줍니다.
# 이미지 데이터 전처리
from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Image augmentation
# train셋에만 적용
train_datagen = ImageDataGenerator(rescale = 1./255, # 모든 이미지 원소값들을 255로 나누기
vertical_flip=True,
fill_mode='nearest'
)
# validation 및 test 이미지는 augmentation을 적용하지 않는다;
# 모델 성능을 평가할 때에는 이미지 원본을 사용 (rescale만 진행)
validation_datagen = ImageDataGenerator(rescale = 1./255)
test_datagen = ImageDataGenerator(rescale = 1./255)# flow_from_directory() 메서드를 이용해서 훈련과 테스트에 사용될 이미지 데이터를 만들기
# 변환된 이미지 데이터 생성
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=16, # 한번에 변환된 이미지 16개씩 만들어라 라는 것
color_mode='grayscale', # 흑백 이미지 처리
class_mode='binary',
target_size=(150,150)) # target_size에 맞춰서 이미지의 크기가 조절된다
validation_generator = validation_datagen.flow_from_directory(validation_dir,
batch_size=4,
color_mode='grayscale',
class_mode='binary',
target_size=(150,150))
test_generator = test_datagen.flow_from_directory(test_dir,
batch_size=4,
color_mode='grayscale',
class_mode='binary',
target_size=(150,150))
# 참고로, generator 생성시 batch_size x steps_per_epoch (model fit에서) <= 훈련 샘플 수 보다 작거나 같아야 한다.# 합성곱 신경망 모델 구성하기
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(512, (3,3), activation='relu', input_shape=(150, 150, 1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary() # 신경망의 구조 확인그 다음 원하는 모델을 정의하고,
from tensorflow.keras.optimizers import RMSprop
# compile() 메서드를 이용해서 손실 함수 (loss function)와 옵티마이저 (optimizer)를 지정
model.compile(optimizer=RMSprop(learning_rate=0.001), # 옵티마이저로는 RMSprop 사용
loss='binary_crossentropy', # 손실 함수로 ‘binary_crossentropy’ 사용
metrics= ['accuracy'])
# RMSprop (Root Mean Square Propagation) Algorithm: 훈련 과정 중에 학습률을 적절하게 변화시킨다
손실 함수로 binary_crossentropy 를 사용하여 이진분류하였고,
옵티마이저로 RMSprop를 사용하였습니다 해당 알고리즘은 훈련과정에서 학습률을 적절하게 변화시켜주는 장점이 있습니다.
import os
from keras.callbacks import EarlyStopping, ModelCheckpoint
# earlystopping은 (patience 수)n번 epoch통안 val_loss 개선이 없다면 학습을 멈춥니다.
early_stop = EarlyStopping(monitor='val_loss', patience=5)
model_path = 'C:\\Users\\Happy\\Desktop\\help'
filename = os.path.join(model_path,'ox_class_cnn.h5')
checkpoint = ModelCheckpoint(filename, #filepath
monitor='val_loss',#모델 저장시 기준이 되는 값 => val_loss는 loss가 가장 적을 때 저장
verbose=1, # 이게 1 이면 저장되었다고 표시됨
save_best_only=True, # True의 경우 학습 중 현 시점 가장 좋은 모델로 저장됨
save_weights_only=True, # True의 경우 모델 레이어 및 가중치도 저장됨
# save_freq = BATCH_SIZE, # 'epoch'을 사용할 경우, 매 에폭마다 모델이 저장됩니다. integer을 사용할 경우, 숫자만큼의 배치를 진행되면 모델이 저장됩니다.
mode='auto'# val_acc 인 경우, 정확도이기 때문에 클수록 좋습니다. 따라서 이때는 max를 입력해줘야합니다. 만약 val_loss 인 경우, loss 값이기 때문에 값이 작을수록 좋습니다. 따라서 이때는 min을 입력해줘야합니다. auto로 할 경우, 모델이 알아서 min, max를 판단하여 모델을 저장합니다.
)# 모델 훈련
history = model.fit_generator(train_generator, # train_generator안에 X값, y값 다 있으니 generator만 주면 된다
validation_data=validation_generator, # validatino_generator안에도 검증용 X,y데이터들이 다 있으니 generator로 주면 됨
steps_per_epoch=4, # 한 번의 에포크(epoch)에서 훈련에 사용할 배치(batch)의 개수 지정; generator를 4번 부르겠다
epochs=100, # 데이터셋을 한 번 훈련하는 과정; epoch은 100 이상은 줘야한다
validation_steps=4, # 한 번의 에포크가 끝날 때, 검증에 사용되는 배치(batch)의 개수를 지정; validation_generator를 4번 불러서 나온 이미지들로 작업을 해라
verbose=2,
callbacks=[early_stop, checkpoint]
)
# 참고: validation_steps는 보통 내가 원하는 이미지 수에 flow할 때 지정한 batchsize로 나눈 값을 validation_steps로 지정그 다음 모델 훈련을 하고,
model.load_weights('ox_class_cnn.h5') #저장된 최적 모델 불러옴 끄면 그냥 최종 모델 사용가능# 모델 성능 평가
model.evaluate(train_generator)
# 모델 성능 평가
model.evaluate(test_generator)
저는 이 정도 정확도가 나오네요.. 데이터가 적을 수도 있으니 데이터를 늘려보는것도 좋을것 같습니다!
일봉을 시간봉으로 대체 한다거나 여러 방법이 있을 수 있겠네요
# 정확도 및 손실 시각화
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'go', label='Training loss')
plt.plot(epochs, val_loss, 'g', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()모델의 성능 평가 및 학습율을 계산합니다.
https://velog.io/@eodud0582/cnn-ox-image-classification
해당 블로그를 참조하여 다음날 주가 예측에 활용하였습니다,!! 질문있으시거나 수정사항 요청은 댓글 부탁드릴께요~
#### 추가 된 내용
외국인 순매수 수량데이터를 추가하여 이미지 화 하려고 하였습니다.
색을 인식할 수 있게 바꾸었습니다.
데이터 전처리
데이터 3중 분류 및 컬러로 구분
'IT - 코딩 > AI, 예측모델' 카테고리의 다른 글
| 자연어처리 긍부정 판단 with python & pytorch (bert) (2) | 2022.11.19 |
|---|---|
| 딥러닝을 응용한 환율예측으로 가상화폐 차익거래 기회 백테스팅 (2) 수익율 측정 (2) | 2022.09.08 |
| 딥러닝을 응용한 환율예측으로 가상화폐 차익거래 기회 백테스팅 (1) (1) | 2022.09.08 |
| DNN을 이용한 분류모델 (with python) (1) | 2022.08.21 |
| 시계열 분해 고장 예측 및 이상치 탐지 (네트워크 지능화를 위한 인공지능 해커톤) 시계열 데이터 이상징후 감지 (1) | 2022.05.28 |



