#data["day_of_week"] = data["날짜"].dt.day_of_week
data["달러환율"] = data["달러환율"].fillna(method="ffill")
data = data.dropna() # 바이낸스 오늘 날짜 까지 안받아와졋을 경우에(업비트와 데이터 차이)
data.isna().sum()# 사용할 모든 파일 리스트로 읽어오기
import os
import numpy as np
import pandas as pd
import math #math 모듈을 먼저 import해야 한다.
import matplotlib.pyplot as plt
os_file_list = os.listdir('C:/Users/Happy/Desktop/논문용/krwusdtdata/전처리된파일')
read_path = "C:\\Users\\Happy\\Desktop\\논문용\\krwusdtdata\\전처리된파일\\"
# 딕셔너리 안에 모든 데이터 프레임 저장
All_data = {}
for files in os_file_list:
print(files)
df= pd.read_csv(read_path+files, encoding = "cp949")
All_data[files[:-4]] = df
key_list = list(All_data.keys())
data = All_data.copy()
key_list = list(set(key_list) - {"BTC_KRW","bin_data"})
key_list첫 부분은 이전 포스팅과 동일하고,
def For_LSTM_DATA(All_data,key_list):
# All_data , key_list
for i in range(len(key_list)):
print(key_list[i])
print(All_data[key_list[i]].info())
# All_data[key_list[i]] = All_data[key_list[i]]
def set_index(df):
df['time'] = pd.to_datetime(df['time'], format='%Y-%m-%d', errors='raise')
df = df.set_index('time',drop=False)
return df
Use_data = {}
# All_data , key_list
for i in range(len(key_list)):
# print(key_list[i])
# print(All_data[key_list[i]].info())
Use_data[key_list[i]] = All_data[key_list[i]].copy() # [["time","Open"]]
# All_data[key_list[i]] = All_data[key_list[i]]
for i in range(len(key_list)):
print(key_list[i],i)
Use_data[key_list[i]] = set_index(Use_data[key_list[i]])
# 기간 조정
pariod_min_list = [Use_data[key_list[i]].index.min() for i in range(len(key_list)) ]
pariod_max_list = [Use_data[key_list[i]].index.max() for i in range(len(key_list)) ]
pariod_start = max(pariod_min_list)
pariod_end = min(pariod_max_list)
print("시작일 교집합 : ",pariod_start)
print("최종일 교집합 : ",pariod_end)
#날짜 조정.(모든 사용할 데이터들의 날짜를 같게 조정함.)
for i in range(len(key_list)):
Use_data[key_list[i]] = Use_data[key_list[i]].loc[Use_data[key_list[i]]["time"].between(pariod_start,pariod_end)]
# 모든 컬럼명을 데이터 프레임 이름으로 바꿈
for i in range(len(key_list)):
col_list = list(Use_data[key_list[i]].columns)
col_list = list(set(col_list) - {"time"})
for j in range(len(col_list)):
print(key_list[i]+"_"+col_list[j])
Use_data[key_list[i]] = Use_data[key_list[i]].rename(columns={col_list[j]:key_list[i]+"_"+col_list[j]})
ALL_DATA_BY_USE = pd.DataFrame()
for i in range(len(key_list)):
# Use_data[key_list[i]]
print(len(Use_data[key_list[i]]),key_list[i])
if i == 0: # 처음시작만 @ 또는 가장 길이가 긴 값!!!!(날짜)
ALL_DATA_BY_USE = Use_data[key_list[i]]
else:
ALL_DATA_BY_USE = pd.concat([ALL_DATA_BY_USE,Use_data[key_list[i]]],axis = 1)
# try:
# del ALL_DATA_BY_USE["time"]
# except:
# pass
ALL_DATA_BY_USE = ALL_DATA_BY_USE.fillna(method="ffill")
if (len(ALL_DATA_BY_USE) == len(ALL_DATA_BY_USE.drop_duplicates())): # 중복데이터가 더 없는지 확인
pass
else:
print("길이가 다름")
# try:
# del ALL_DATA_BY_USE["time"]
# except:
# pass
try:
del ALL_DATA_BY_USE["time"]
except:
pass
# 이렇게 설정하면 다음날 얼마나 오르고 내리는지 예측하게 됨.
ALL_DATA_BY_USE["KRW_USDT_High - KRW_USDT_Open"] = ALL_DATA_BY_USE["KRW_USDT_High"] - ALL_DATA_BY_USE["KRW_USDT_Open"] # 변동성
ALL_DATA_BY_USE["KRW_USDT_Open_shift_1"] = ALL_DATA_BY_USE[["KRW_USDT_Open"]].shift(-1) #다음날 시작가 데이터 까지 가지고 시작
# 일단 다음날 시가를 예측해보자.!!
use_columns = list(ALL_DATA_BY_USE.columns)
print(use_columns)
target = "KRW_USDT_Open"#"KRW_USDT_High - KRW_USDT_Open" # "KRW_USDT_Open"
ALL_DATA_BY_USE = ALL_DATA_BY_USE.dropna()
print(ALL_DATA_BY_USE[[target]])
from statsmodels.tsa.seasonal import seasonal_decompose
target_col = seasonal_decompose(ALL_DATA_BY_USE[target], model = 'additive' ,period = 500, extrapolate_trend = 1)
fig = plt.figure()
fig = target_col.plot()
fig.set_size_inches(15,12)
ALL_DATA_BY_USE[target+'col_trend'] = target_col.trend
ALL_DATA_BY_USE[target+'col_seasonal'] = target_col.seasonal
ALL_DATA_BY_USE[target+'col_resid'] = target_col.resid
col_index = ['KRW_USDT_Open', 'KRW_USDT_High', 'KRW_USDT_Low', 'KRW_USDT_Close',
'미국금리_Open', '독일_Open', '독일_High', '독일_Low', '독일_Close',
'중화인민공화국 상해종합_Open', '중화인민공화국 상해종합_High', '중화인민공화국 상해종합_Low',
'중화인민공화국 상해종합_Close', '니케이 225_Open', '니케이 225_High', '니케이 225_Low',
'니케이 225_Close', '한국금리_Open', '코스피_Open', '코스피_High', '코스피_Low',
'코스피_Close', 'DXY_Open', 'DXY_High', 'DXY_Low', 'DXY_Close',
'krx_100_Open', 'krx_100_High', 'krx_100_Low', 'krx_100_Close',
'KRW_CNY_Open', 'KRW_CNY_High', 'KRW_CNY_Low', 'KRW_CNY_Close',
'프랑스_Open', '프랑스_High', '프랑스_Low', '프랑스_Close', 'KRW_EUR_Open',
'KRW_EUR_High', 'KRW_EUR_Low', 'KRW_EUR_Close',
'KRW_USDT_High - KRW_USDT_Open', 'KRW_USDT_Open_shift_1',
'KRW_USDT_Opencol_trend', 'KRW_USDT_Opencol_seasonal',
'KRW_USDT_Opencol_resid']
ALL_DATA_BY_USE = ALL_DATA_BY_USE[col_index]
return ALL_DATA_BY_USE, target
ALL_DATA_BY_USE,target = For_LSTM_DATA(All_data,key_list)전 포스팅과 동일한 부분(전처리등) 은 함수로 만들어 버렸다.
from keras.models import Sequential
from keras.layers import Dense, LSTM, Conv1D, Lambda
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.layers import LSTM, GRU
import keras
from tensorflow.keras.losses import Huber
from tensorflow.keras.optimizers import Adam
from keras.layers import Input, LSTM, Dense
from keras.layers import Flatten
from keras.layers import Dropout
from tensorflow.keras import optimizers
from keras import layers
import tensorflow as tf
from keras import losses
elu = tf.nn.elu
model = keras.models.Sequential([
keras.layers.Input(shape=(x_train_WINDOW.shape[1] , x_train_WINDOW.shape[2])),
keras.layers.LSTM(1024, return_sequences=True, name='LSTM_0'),
keras.layers.LSTM(512, return_sequences=True, name='LSTM_1'),
keras.layers.LSTM(256, return_sequences=True, name='LSTM_2'),
keras.layers.LSTM(128, return_sequences=True, name='LSTM_3'),
keras.layers.Flatten(),
keras.layers.Dense(64, activation=elu),
keras.layers.Dense(1, activation=elu)
# keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss=Huber(), optimizer=Adam(0.000001), metrics=['mse']) #0.001이 기본 러닝 레이트이부분도 전 포스팅 복붙.
filename_2 = "USDT_LSTM_환율변동성예측_MSE 87 64by4.h5"
model.load_weights(filename_2) #저장된 최적 모델 불러옴 끄면 그냥 최종 모델 사용가능여기서부터 다시 . 모델의 학습없이 저번에 만든 모델을 가져온다.
pred = model.predict(x_test_WINDOW) #예측값(실제)
actual = np.asarray(y_test_WINDOW)
pred = pd.DataFrame(pred,columns = ["예측값"]).apply(lambda x : (x * (MAX_val - MIN_val) + MIN_val)) # 원래 값 복원
actual = pd.DataFrame(actual,columns = ["실제값"]).apply(lambda x : (x * (MAX_val - MIN_val) + MIN_val)) # 예측 값 복원
print(pred.shape, actual.shape)
i = 0
j = len(pred)
plt.figure(figsize=(12, 9))
plt.title('test_data')
plt.plot(actual[i:j], label='actual')
plt.plot(pred[i:j], label='prediction')
plt.legend()
plt.show()
from sklearn.metrics import mean_absolute_error, mean_squared_error
print("MSE",mean_squared_error(actual["실제값"],pred["예측값"]))
rmse = mean_squared_error(actual["실제값"],pred["예측값"], squared=False)
print("rmse = {}".format(rmse))
전 포스팅보다 좋은 모델인 LSTM이다.
bin_data = data["bin_data"]
up_data = data["BTC_KRW"]
Usdt_data = data["KRW_USDT"]
####################
up_data = up_data.loc[~(up_data["Open"] == 0)]# 업비트 이상치 제거
data = pd.merge(up_data, Usdt_data, on = "time", how = "left")
data = pd.merge(data, bin_data, on = "time", how = "left") # 업비트 기준으로 맞는 잘짜 데이터끼리만 보여줌.
#################
def set_index(df):
df['time'] = pd.to_datetime(df['time'], format='%Y-%m-%d', errors='raise')
df = df.set_index('time',drop=True)
return df
data = set_index(data)
data = pd.DataFrame({"날짜":data.index,
"비트코인한국":data.Open_x.values,
"바이낸스USDT(달러)":data.Open.values,
"달러환율":data.Open_y.values,
})
data해당부분은 환율과 업비트 가격, 바이낸스 가격을 가져온 부분이다. 데이터를 가져온 후, 데이터의 시간을 맞게 조정한 부분이다.
#data["day_of_week"] = data["날짜"].dt.day_of_week
data["달러환율"] = data["달러환율"].fillna(method="ffill")
data = data.dropna() # 바이낸스 오늘 날짜 까지 안받아와졋을 경우에(업비트와 데이터 차이)
data.isna().sum()ffill로 전값으로 채운 이유는 환율데이터는 주말에 없기 때문. 그래서 None값에 주말가격을 채운다.
# 9시인것을 다 뺴버려서 다시 맞추어줌.
data["날짜_2"] = [str(data["날짜"][i])[:-8]+"09:00" for i in range(len(data["날짜"]))]
data["날짜_2"] = pd.to_datetime(data['날짜_2'], format='%Y-%m-%d %H:%M', errors='raise')
# 서버 점검일 or 비트코인 전송 불가일
up_sutdown = [("2018-04-16 20:00", "2018-04-17 00:00"),
("2018-04-24 07:59", "2018-04-24 08:30"),
("2018-06-15 04:00", "2018-06-15 05:00"),
("2018-08-22 02:00", "2018-08-22 07:00"),
("2018-10-18 02:00", "2018-10-18 03:00"),
("2018-12-05 03:00", "2018-12-05 04:00"),
("2018-12-12 03:00", "2018-12-12 04:00"),
("2019-01-01 01:00", "2019-01-01 03:00"),
("2019-03-20 02:00", "2019-03-20 06:00"),
("2019-03-24 03:00", "2019-03-24 04:00"),
("2020-01-31 02:00", "2020-01-31 05:00"),
("2021-01-07 05:00", "2021-01-07 06:00"),
("2021-03-03 03:30", "2021-03-03 06:30"),
("2021-03-14 03:00", "2021-03-14 06:00"),
("2021-03-23 03:00", "2021-03-23 06:00"),
("2021-06-30 23:00", "2021-07-01 03:00"),
("2019-10-17 21:00", "2019-10-18 13:00"),
("2019-04-10 21:50", "2019-04-17 02:00"),
("2019-12-12 23:55", "2019-12-13 03:00"),
("2019-12-15 00:00", "2019-12-15 01:00"),
("2020-12-29 01:30", "2020-12-29 02:25"),
("2020-12-30 19:01", "2021-01-01 05:02"),
("2021-06-29 21:01", "2021-07-01 04:51"),
# ("2001-01-02" , "2018-04-10"), # trian 기간 제외
("2022-07-19" , "2022-08-02") # LSTM데이터 셋과 타임테이블 맞춤
]
# 서버 점검일이 아닌 날짜만 받기
for i in range(len(up_sutdown)):
data = data.loc[~(data["날짜_2"].between(up_sutdown[i][0],up_sutdown[i][1]))]차익거래 시 코인이 전송이 안되는 경우가 있다. 그 경우에는 가격차이가 매우 많이 벌어지거나 하는데 사실상 코인의 전송이 불가한 상태일 경우가 많다. 그렇다면 나는 김프매매를 사용할 경우 헷징을 해도 한게 아니게 된다. (전송 불가 상태는 차익실현 불가)
그래서 업비트 서버 점검일과 비트코인 전송 불가인 시간대들을 가져와서 해당 때의 날짜를 제거하였다.(시간을 더 추가하면 추가한만큼 빠진다.)
# 예측값 컬럼별로 넣기.
ALL_DATA_BY_USE["time"] = ALL_DATA_BY_USE.index
ALL_DATA_BY_USE = ALL_DATA_BY_USE.reset_index(drop = True)
def inverse_transform_(x):
x = x * (MAX_val - MIN_val) + MIN_val
return x
from tqdm import tqdm
vals = []
for i in tqdm(range(len(data))):
# data 셋의 날짜와 LSTM에서 쓸 값의 날짜의 인덱스를 맞추어가져롬. 그리고 해당 날짜에 맞게 데이터 집어넣음.
idx = list(ALL_DATA_BY_USE["time"].values).index(data["날짜"].iloc[i]) + 1 # +1 은 ALL_DATA_BY_USE의 컬럼이 0부터 시작하기 떄문
a = model.predict(x_WINDOW[idx-WINDOW_SIZE-1:idx-WINDOW_SIZE])
a = inverse_transform_(a)
vals.append(float(a))
data["LSTM예측값"] = vals # 빠진날도 있어서 이렇게 해야함..사용할데이터 셋과 LSTM에서 사용할 날짜의 인덱스를 맞추기 위한 함수이다. 이렇게 하면 된다.
이부분에서 LSTM에서 값들을 가지고 와 예측하고 예측한 값을 data에 넣는다 (수익율 계산을 편하게 하려고.)
시간좀 걸리니 # data.to_csv("data.csv") 로 세입하자..
===============추가 가정=================================
항상 하던 생각이 있었다. 내 생각엔 환율이 높아지면 평균 김프가 약해지고 환율이 낮으면 평균 김프가 높아진다.
df = data[["프리미엄가","달러환율","재측정달러가치"]]
from sklearn.linear_model import LinearRegression
X = df["달러환율"].values
Y = df["프리미엄가"].values
train_X = pd.DataFrame(X, columns=['X'])
train_Y = pd.Series(Y)
lrmodel = LinearRegression()
lrmodel.fit(train_X, train_Y)
data["재측정달러가치_예상김프"] = lrmodel.predict(data[["재측정달러가치"]].values)
data["달러환율_예상김프"] = lrmodel.predict(data[["달러환율"]].values)
data["LSTM예측값_예상김프"] = lrmodel.predict(data[["LSTM예측값"]].values)
data.corr()["프리미엄가"]["달러환율_예상김프"],data.corr()["프리미엄가"]["재측정달러가치_예상김프"]그것을 확인하기 위해 단순 선형모델을 만들어 보았다.
밑에서 예상김프는 선형회귀로 예측 한다!!!
# # 데이터 프레임 내 데이터 시각화
import math #math 모듈을 먼저 import해야 한다.
import matplotlib.pyplot as plt
# 데이터 프레임 모든 컬럼 그리기
# 함수명으로도 정의하기
def columns_plot(data): # y좌표
col_list_plt = list(data.select_dtypes(include = ["float","int"]).columns)
x_plt_n = 3 # 한번에 그릴 plt x 축 수
y_plt_n = 4 # 한번에 그릴 plt y 축 수
w_space = 0.2 # float("0."+str(x_plt_n)
h_space = 0.2 # float("0."+str(y_plt_n)
if (x_plt_n < math.ceil(len(col_list_plt) / y_plt_n)):
x_plt_n = math.ceil(len(col_list_plt) / y_plt_n)
#plot 이쁘게
f, axes = plt.subplots(x_plt_n, y_plt_n)
f.set_size_inches((20, 15))
plt.subplots_adjust(wspace = w_space, hspace = h_space)
for i in range(len(col_list_plt)):
bb = math.ceil(((i )// y_plt_n))
axes[bb][i - math.ceil(((i )// y_plt_n)) * y_plt_n].plot(data[col_list_plt[i]],label = col_list_plt[i] )#, color = 'blue', marker = 'o')
axes[bb][i - math.ceil(((i )// y_plt_n)) * y_plt_n].set_title(col_list_plt[i])
plt.show()
columns_plot(data)위 함수는 전에도 포스팅 한적이 한번 있지만, 모든 컬럼을 시각화하기 편하게 만든 함수이다. 데이터를 보면..

김프가 - 60을 찍었던 적이 몇번 있다.

날짜를 확인해보니 매우 옛날이다.. 일단 인지하고,
df1 = data[["달러환율","프리미엄가"]]
from sklearn.preprocessing import MinMaxScaler #StandardScaler RobustScaler
Scaler = MinMaxScaler()
df1 = Scaler.fit_transform(data[["달러환율","프리미엄가"]])
df1 = pd.DataFrame(df1,columns = ["달러환율","프리미엄가"])
sns.pairplot(df1)
sns.regplot(x = '달러환율', y = '프리미엄가', data = df) # 단순 선형회귀 리그레션값을 바로 보여줌.
## 시각화
fig = plt.figure(figsize=(8,8))
fig.set_facecolor('white')
font_size = 15
plt.scatter(df1['달러환율'],df1['프리미엄가']) ## 원 데이터 산포도
plt.xlabel('달러환율', fontsize=font_size)
plt.ylabel('프리미엄가',fontsize=font_size)
plt.show()
from statsmodels.formula.api import ols
fit = ols('프리미엄가 ~ 달러환율',data=df).fit() ## 단순선형회귀모형 적합
뭔가 조금 분산이 심한 .. 회귀모형이다.. 설명력등이 좋진 않다.
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
mpl.rcParams['axes.unicode_minus'] = False
# 그래프에서 한글 폰트 깨지는 문제에 대한 대처(전역 글꼴 설정)
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname='c:/Windows/Fonts/malgun.ttf').get_name()
rc('font', family=font_name)
# sns.clustermap(data.corr(),
# annot = True, # 실제 값 화면에 나타내기
# cmap = 'RdYlBu_r', # Red, Yellow, Blue 색상으로 표시
# vmin = -1, vmax = 1, #컬러차트 -1 ~ 1 범위로 표시
# )
df1 = data.corr()
# 그림 사이즈 지정
fig, ax = plt.subplots( figsize=(7,7) )
# 삼각형 마스크를 만든다(위 쪽 삼각형에 True, 아래 삼각형에 False)
mask = np.zeros_like(df1, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 히트맵을 그린다
sns.heatmap(df1,
cmap = 'RdYlBu_r',
annot = True, # 실제 값을 표시한다
mask=mask, # 표시하지 않을 마스크 부분을 지정한다
linewidths=.5, # 경계면 실선으로 구분하기
cbar_kws={"shrink": .5},# 컬러바 크기 절반으로 줄이기
vmin = -1,vmax = 1 # 컬러바 범위 -1 ~ 1
)
plt.show()

피어슨 상관계수표이다. 일단 인지 하고 넘어가자.
===========================================
Measure_Usdt = 1
seed = 1000000
up_fee = 0.0005
bin_fee = 0.0001
send_fee = 0.0009
up_to_bin_pre = 0.01
bin_to_up_pre = 0.15
data["바이낸스달러환산"] = data["달러환율"] * data["바이낸스USDT(달러)"]
data["프리미엄가"] = (1- data["비트코인한국"] / data["바이낸스달러환산"])
data["재측정달러가치"] = ((Measure_Usdt / data['바이낸스USDT(달러)']) *data['비트코인한국']) / Measure_Usdt
info = {"state": False, "enter_price": 0, "enter_time": None, "exit_price": 0, "ror": 1, "fiat_money": seed}
info_dataFrame = pd.DataFrame(info, index=[0])
data = data.reset_index(drop = True)
data여러가지 기본 정보들이다.
업비트 시장가 수수료
바이낸스 시장가 수수료
업비트 비트코인 정송수수료
up_to_bin_pre 은 차익거래 시 역~약김프에 받아서 약손해/수익을 볼 % 이고
bin_to_up_pre 은 차익거래시 강김프에 다시 받아서 수익을 볼 %이다
재측정 달러가치는 비공식 환율이다. 사실 환율은 누군가가 책정해주는것이다. 이것을 잘 생각해보기 바란다. 비공식환율이라고 검색해보면 될것이다.
info_dataFrame으로 수익율 측정을 위해 만들었다. 더 좋은 방법이 있을것 같기도 한데 지금은 이방식밖에 안떠오른다.
# 기간에 따른 수익율 재측정.
data = data.loc[(data["날짜"].between("2020-01-01","2024-01-01"))].reset_index(drop = True)
data2020~ 2022오늘까지.(7.18일)로 측정해본 결과
def fun_cheak_ror(data,seed,info_dataFrame):
a = 1
for i in range(len(data)):
seed1 = seed
# if ((data["LSTM예측값_예상김프"][i] - data["프리미엄가"][i])>0) and (info['state'] == False):
# 현재 내 시드(원화/달러가치)가 전송 후 판매까지 완료한 달러가치보다 큰경우 => 내가 외국 거래소에서 환전 받을때 더 수익을 보는 경우.
# if (float(seed / data['달러환율'][i]) <= (float((info["fiat_money"] / data['비트코인한국'][i] * (1 - up_fee)- send_fee) * data['바이낸스USDT(달러)'][i] * (1 - bin_fee) ))) and (info['state'] == False):
# 김프가 # 현재 내 시드(원화/달러가치)가 전송 후 판매까지 완료한 달러가치보다 큰경우
# if (data["프리미엄가"][i] < up_to_bin_pre) and ((float(seed / data['달러환율'][i]) <= (float((info["fiat_money"] / data['비트코인한국'][i] * (1 - up_fee)- send_fee) * data['바이낸스USDT(달러)'][i] * (1 - bin_fee) ))) and (info['state'] == False)):
# if ((data['프리미엄가'][i]) <= up_to_bin_pre) and (info['state'] == False): # 프리미엄이 0보다 작고 포지션이 없다면
# if ((data['프리미엄가'][i]) <= up_to_bin_pre) and (info['state'] == False) and (data["달러환율"][i] < data["재측정달러가치"][i]): # 프리미엄이 0보다 작고 포지션이 없다면
# if (info['state'] == False) and (data["달러환율"][i] > data["재측정달러가치"][i]): # 프리미엄이 0보다 작고 포지션이 없다면
# if (data["달러환율"][i] < data["LSTM예측값"][i]) and (info['state'] == False):
if (data["프리미엄가"][i] > data["LSTM예측값_예상김프"][i]) and (info['state'] == False) : # 역프일때 바로진입하지 않고 더 많은 수익을 볼 수 있군
# print("if문 통과 포지션 진입",data["프리미엄가"][i] , data["LSTM예측값_예상김프"][i])
info["state"] = True # 바이낸스로 차익봄
info["enter_price"] = data['비트코인한국'][i]
info["enter_time"] = data['날짜'][i]
info["exit_price"] = data['바이낸스USDT(달러)'][i]
seed_usdt = float((info["fiat_money"] / data['비트코인한국'][i] * (1 - up_fee) - send_fee) * data['바이낸스USDT(달러)'][i] * (1 - bin_fee)) # 달러로 가질돈
new_info_dataFrame = pd.DataFrame(info, index=[0])
info_dataFrame = pd.concat([info_dataFrame, new_info_dataFrame], axis=0) # 수익 데이터 저장
a = 0
# info["ror"] = None
# if (((data['프리미엄가'][i]) >= bin_to_up_pre) and (info['state'] == True)): # 프리미엄이 0보다 크고 포지션이 없다면
elif (a != 1) and((float(seed * (1 + bin_to_up_pre)) < (float(((seed_usdt / data['바이낸스USDT(달러)'][i]) * (1 - bin_fee) - send_fee) * data['비트코인한국'][i] * (1 - up_fee)))))and (info['state'] == True):
# print("if문 통과 포지션 탈출",float(seed * (1 + bin_to_up_pre)) , (float(((seed_usdt / data['바이낸스USDT(달러)'][i]) * (1 - bin_fee) - send_fee) * data['비트코인한국'][i] * (1 - up_fee))))
info["state"] = False # 업비트로 재전송
info["enter_price"] = data['바이낸스USDT(달러)'][i]
info["enter_time"] = data['날짜'][i]
info["exit_price"] = data['비트코인한국'][i]
seed = info["fiat_money"] = float(((seed_usdt / data['바이낸스USDT(달러)'][i]) * (1 - bin_fee) - send_fee) * data['비트코인한국'][i] * (1 - up_fee))
# print(info["fiat_money"])
info["ror"] = seed / seed1
new_info_dataFrame = pd.DataFrame(info, index=[0])
info_dataFrame = pd.concat([info_dataFrame, new_info_dataFrame], axis=0) # 수익 데이터 저장
return info_dataFrame함수로 수익 구조를 정의했다. 설명하면 복잡한데 LSTM으로 예측한 값을 단순선형회귀모델로 다시 예측하여 내 예상 (하루뒤)프리미엄이 현재 프리미엄값이 작을경우 바이낸스로 보낸 후 매도 하고, 다시내가 비트코인을 바이낸스에서 업비트로 전송 후 시드가 맨 처음 보내는 시드의 수익율이 bin_to_up_pre보다 클 경우에 수익을 실현하는 구조이다.(
잃지 않는 경우에서만 작동.)
# data = data.loc[~(abs(data["프리미엄가"])>0.1)].reset_index(drop = True)
a = 1
seed = 1000000
bin_to_up_pre = 0.01
info = {"state": False, "enter_price": 0, "enter_time": None, "exit_price": 0, "ror": 1, "fiat_money": seed}
info_dataFrame = pd.DataFrame(info, index=[0])
info_dataFrame_ror = fun_cheak_ror(data,seed,info_dataFrame)
info_dataFrame = info_dataFrame_ror.reset_index(drop = True)
print("ror : ",(info_dataFrame["fiat_money"][len(info_dataFrame)-1])/(info_dataFrame["fiat_money"][0]))
info_dataFrame

시드 1000000원 으로
2년 7개월 기간동안 ror이
979.2499988684285거의 980배 가량의 수익을 볼 수 있었다.

말도 안되는 수익율이라 불만이 있을 수 있다.
plt.plot(info_dataFrame["ror"])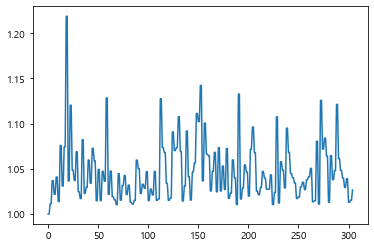
한번에 큰 수익이 났는지 검사해본 결과 그렇지 않았고

평균적으로 4%수익을 본다는 결과를 도출해내었다.
정리하자면, 2년 7개월간 ror이 979.24이다. 리스크는 오직 전송시간에서만 존재한다
etc )
if 문을 바꾸어 진입시점을 바꿔 수익율을 측정해보면
현재 내 시드(원화/달러가치)가 전송 후 판매까지 완료한 달러가치보다 큰경우 => 내가 외국 거래소에서 환전 받을때 더 수익을 보는 경우.
if (float(seed / data['달러환율'][i]) <= (float((info["fiat_money"] / data['비트코인한국'][i] * (1 - up_fee)- send_fee) * data['바이낸스USDT(달러)'][i] * (1 - bin_fee) ))) and (info['state'] == False):
이때의 ror
ror : 565.9479845776145
# 김프가 # 현재 내 시드(원화/달러가치)가 전송 후 판매까지 완료한 달러가치보다 큰 경우
if (data["프리미엄가"][i] < up_to_bin_pre) and ((float(seed / data['달러환율'][i]) <= (float((info["fiat_money"] / data['비트코인한국'][i] * (1 - up_fee)- send_fee) * data['바이낸스USDT(달러)'][i] * (1 - bin_fee) ))) and (info['state'] == False)):
이때의 ror
ror : 1.0486445986482573김프가 내가 원하는 약손/수익율 (up_to_bin_pre) 보다 작다면,
if ((data['프리미엄가'][i]) <= up_to_bin_pre) and (info['state'] == False):
이때의 ror
ror : 2.1624916626924153프리미엄이 0보다 작고 포지션이 없다면
if (info['state'] == False) and (data["달러환율"][i] > data["재측정달러가치"][i]):
이때의 ror
ror : 788.650121027822LSTM환율 예측값보다 달러환율이 낮다면
if (data["달러환율"][i] < data["LSTM예측값"][i]) and (info['state'] == False):
이때의 ror
ror : 12.040631083935116
if (data["프리미엄가"][i] > data["LSTM예측값_예상김프"][i]) and (info['state'] == False) :
이때의 ror
ror : 979.2499988684285
'IT - 코딩 > AI, 예측모델' 카테고리의 다른 글
| 자연어 처리 _ 구문 속 질의응답 모델(QA) with python & pytorch (코랩 pro 사용) (0) | 2023.01.03 |
|---|---|
| 자연어처리 긍부정 판단 with python & pytorch (bert) (2) | 2022.11.19 |
| 딥러닝을 응용한 환율예측으로 가상화폐 차익거래 기회 백테스팅 (1) (1) | 2022.09.08 |
| DNN을 이용한 분류모델 (with python) (1) | 2022.08.21 |
| 시계열 분해 고장 예측 및 이상치 탐지 (네트워크 지능화를 위한 인공지능 해커톤) 시계열 데이터 이상징후 감지 (1) | 2022.05.28 |


