과거에 맹준성 대표님이자 BIT박사님 옵션 논문 데이터 관련 도와드리면서 작성했던 코드입니다. 정상작동은 하지만, 코드가 조금 너저분 할것 같습니다.
조금 옛날에 작성한 코드가 좀 부끄럽네요.. 일단 보여드리겠습니다.
먼저 해당 파일의 목적은 그 전주 목요일과 이번 주 목요일을 가지고 1개의 봉으로 만드는 과정입니다.
아래의 out_put 함수에서 start_dayofweek는 그 전 주 요일 중 시작일 end_dayofweek는 다음 주 요일 중 끝나는 요일입니다.
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from tqdm import tqdm
save_path = "C:\\Users\\Happy\\Desktop\\맹박사님\\data\\"
# yes traider 파일
KRW_USDT = pd.read_csv("Kospi_Spot.csv" , encoding = "cp949",names = ['날짜',"오픈","고가","저가","종가"])
def Pretreatment_by_yes_trader(df): #데이터 가이드에서 다운한 데이터 전처리
df["날짜"] = [df["날짜"][i][0:4]+"-"+df["날짜"][i][5:7]+"-"+df["날짜"][i][8:10] for i in range(len(df["날짜"]))]
df['날짜'] = pd.to_datetime(df['날짜'], format='%Y-%m-%d', errors='raise')
# 예스트레이더는 장이 열려있으면 데이터를 이상하게 주기 떄문에 중복제거, 인덱스 초기화 를 하였음
df = df.sort_values(['날짜'],ascending= True).drop_duplicates('날짜').reset_index(drop = True).rename(columns={'날짜':'time'})
return df
df = Pretreatment_by_yes_trader(KRW_USDT)예스트레이더에서 받은 데이터 가공해서

간단한 데이터 프레임으로 표현합니다.
df.loc[(df.year_of_month == 12)&(df.weekofyear == 1)]달과 연도를 파악하기 위해 이렇게 나누었습니다.
df.loc[(df.year_of_month == 12)&(df.weekofyear == 1),"weekofyear"] = 53
def weekofyear_(date):
if ((date.month == 12) & (date.weekofyear== 1)):
return 53
else:
return date.weekofyear53주가 넘어가면 다음주를 못찾더라구요 54주는 없습니다 파이썬 data패키지엔. 그래소 이런식으로 써주었던거 같고.
df.to_csv("rowdata_spot.csv", encoding = "cp949")
df = df.drop_duplicates()현물 데이터를 가져와 저장하고 혹시모를 중복값을 제거합니다.
def out_put(df, start_dayofweek=4, end_dayofweek=3):
info = {"time": 0, "오픈": 0, "저가": 0, "고가": 0, "종가": None, "시작일": 0}
info_dataFrame = pd.DataFrame(info, index=[0])
df1 = df[["year", "weekofyear"]].drop_duplicates()
for i in tqdm(range(len(df1))):
# for i in range(len(df1)):
df_strat_day = df.loc[(df1.iloc[i, :].year == df.year) & (df1.iloc[i, :].weekofyear == df.weekofyear)].time.iloc[0] # 시작일
while True:
new_df_1 = df.loc[(df.year == df_strat_day.year) & (df.weekofyear == weekofyear_(df_strat_day))]
if len(new_df_1) == 0:
print(df_strat_day, "맨처음 시작일이 시작 요일(목)이 없을 경우")
df_strat_day = df_strat_day - timedelta(weeks=1)
elif len(new_df_1) >= 1:
break
ww = start_dayofweek
while True:
new_df = new_df_1.loc[(new_df_1.day_of_week == ww)]
if (len(new_df) == 0):
ww = ww - 1
if len(new_df) == 1:
break
if ww == -1:
break # 이부분은 이전주로 가야함.
if (ww == -1) and len(new_df_1) >= 1:
# print("지울것. 다른요일만 남은날")
wk = 6
while True:
new_df = new_df_1.loc[(new_df_1.day_of_week == wk)]
if (len(new_df) == 0):
wk = wk - 1
if len(new_df) == 1:
break
if wk == -1:
break # 이부분은 이전주로 가야함.
if len(new_df_1) == 0:
print(df_strat_day, "맨처음 볼 테이블이 없음")
else:
df_end_day = df_strat_day = new_df.time.iloc[0]
df_end_day = df_end_day + timedelta(weeks=1)
while True:
new_df_1 = df.loc[(df.year == df_end_day.year) & (df.weekofyear == weekofyear_(df_end_day))]
if len(new_df_1) == 0:
# print(df_end_day, "끝나는 요일이 시작 요일(금)이 없을 경우")
df_end_day = df_end_day + timedelta(weeks=1)
if (df.iloc[len(df) - 1, :].time < df_end_day):
return info_dataFrame[1:].sort_values(by=["time"]).reset_index(drop=True)
elif len(new_df_1) >= 1:
if (new_df_1.time.iloc[0] < df_strat_day): # 해년도를 넘어간 경우
print("해년도를 넘어간 경우", i)
df_end_day = df_end_day + timedelta(weeks=1)
# new_df_1 = df.loc[(df.year == df_end_day.year) & (df.weekofyear == df_end_day.weekofyear)&(df.time < df_end_day)]
new_df_1 = df.loc[(df.year == df_end_day.year) & (df.weekofyear == weekofyear_(df_end_day))]
break
wk = end_dayofweek
while True: # 다음다음다음 날들을 찾음. 다 없으면 종료..
new_df = new_df_1.loc[(new_df_1.day_of_week == wk)]
if (len(new_df) == 0):
wk = wk + 1
if len(new_df) == 1:
break
if wk == 7:
# if (new_df_1.time.iloc[0] < df_strat_day): # 해년도를 넘어간 경우
# print("해년도를 넘어간 경우",i)
# df_end_day = df_end_day + timedelta(weeks = 1)
# new_df_1 = df.loc[(df.year == df_end_day.year) & (df.weekofyear == df_end_day.weekofyear)]
break # 이부분은 이전주로 가야함.
if (wk == 7) and len(new_df_1) >= 1: #
# print("지울것. 금요일만 남은낧",i)
while True: # 1일 이상인 다음주를 찾음.
df_end_day = df_end_day + timedelta(weeks=1)
new_df_1 = df.loc[(df.year == df_end_day.year) & (df.weekofyear == weekofyear_(df_end_day))]
if len(new_df_1) >= 1:
break
wk = 0
while True:
new_df = new_df_1.loc[(new_df_1.day_of_week == wk)]
if (len(new_df) == 0):
wk = wk + 1
if len(new_df) == 1:
break
# if (new_df_1.time.iloc[0] < df_strat_day): # 해년도를 넘어간 경우
# print("해년도를 넘어간 경우",i)
# df_end_day = df_end_day + timedelta(weeks = 1)
# new_df_1 = df.loc[(df.year == df_end_day.year) & (df.weekofyear == df_end_day.weekofyear)]
# elif
# wk == 7:
if len(new_df_1) == 0:
print(df_end_day, "맨 마지막 볼 테이블이 없음",i)
if len(new_df) == 0:
print(df_end_day, "맨 마지막 볼 테이블이 없음",i)
else:
df_end_day = new_df.time.iloc[0]
df_table = df.loc[(df.time.between(df_strat_day, df_end_day))]
# if len(df_table) >= 6:
# print(i, "========",df_table)
info = {"time": df_end_day, "오픈": df_table.iloc[0,].오픈, "저가": min(df_table.저가.values), "고가": max(df_table.고가.values), "종가": df_table[df_table.time == df_end_day].오픈.iloc[0], "시작일": df_strat_day}
new_info_dataFrame = pd.DataFrame(info, index=[0])
info_dataFrame = pd.concat([info_dataFrame, new_info_dataFrame], axis=0) # 수익 데이터 저장
return info_dataFrame[1:].sort_values(by=["time"]).reset_index(drop=True)진짜 긴데 어느정도 맞습니다. 옵션은 만기일이 목요일이기 때문에 그 전주 목요일과 이번주 목요일 시가를 1개의 봉으로 만듦니다.
고려할 사항이 조금 많았습니다. 휴장인날도 있고 목요일에 장이 쉰다면 그 전날 장이 만기일이라 고려할 사항이 많았습니다.
# 0월 1화 2수 3목 4금 5토 6일
info_dataFrame = out_put(df, start_dayofweek = 3, end_dayofweek = 3)
# info_dataFrame.to_csv("info_dataFrame.csv", encoding = "cp949")위의 함수를 실행.
# info_dataFrame = info_dataFrame.rename(columns = {"진입시점":"시작일"})
info_dataFrame["timedelta"] = info_dataFrame["time"] - info_dataFrame["시작일"]
info_dataFrame['시작일'] = pd.to_datetime(info_dataFrame['시작일'], format='%Y-%m-%d', errors='raise')
for i in range(len(info_dataFrame)):
df_table = df.loc[(df.time.between(info_dataFrame.iloc[i].시작일,info_dataFrame.iloc[i].time))]
if len(df_table) >= 7:
print(df_table)
print(i,"========")위 코드는 오류가 있는지 확인하는 부분입니다. 혹시 7일 이상의 차이가 나는 데이터가 있는지 확인합니다.
WINDOW = 3 # 몇 단튀(ex일)로 할것인지.
# 단순 이동 평균(Simple Moving Average, SMA)
def SMA(data, period=30, column='Close'):
return data[column].rolling(window=period).mean()
# 지수 이동 평균(Exponential Moving Average, EMA)
def EMA(data, period=3, column='Close'):
return data[column].ewm(span=period, adjust=False).mean()
def WMA(data, period=3, column='Close'): #가중이동평균
val = []
for i in range(WINDOW):
val.append(None)
for i in range(len(data)-period):
df = data[[column]].loc[i+1:i+period].reset_index(drop = True)
sum_count_1 = 0
sum_count_2 = 0
for j in range(period):
sum_count_1 = sum_count_1 + (j+1) * float(df.iloc[j].values)
sum_count_2 = sum_count_2 + (j+1)
val.append(sum_count_1/sum_count_2)
return val
def LSMA(data, period=3, column='Close'): # 최소제솝평균..
val = []
for i in range(WINDOW):
val.append(None)
for i in range(len(data)-period):
df = data[[column]].loc[i+1:i+period].reset_index(drop = True)
X = [k+1 for k in range(period)]
Y = [float(df.iloc[k]) for k in range(period)]
LRS = (len(X) * sum([X[i]*Y[i] for i in range(len(X))])- sum(X)*sum(Y)) /(len(X) * sum([X[i]*X[i] for i in range(len(X))]) - sum(X) * sum(X))
LRT = (sum(Y) - LRS * sum(X)) / (len(X))
LRI = LRT + LRS * len(X)
val.append(LRI)
return val
# data, period, column = data, WINDOW, '종가'
def triangular_weighted_moving_average(data, period=20, column='Close'):
val = []
for i in range(WINDOW):
val.append(None)
for i in range(len(data)-period):
df = data[[column]].loc[i+1:i+period].reset_index(drop = True)
A = int(np.ceil((period+0.1)/2)) # N기간을 2로나눔 (소수점 반올림)
B = float(df.iloc[0:A].mean()) #A기간동안의 이동평균값
for_Trima = list(df[column].values)
for_Trima.insert(0, B)
Trima = np.mean(for_Trima)#B값의 A기간 이동평균값
val.append(np.mean(Trima))
return val기술적 기표들입니다. 이동평균선 , 지수이동평균, 가중이동평균, 최소제곱 평균, 삼각 가중 이동 평균
이 세가지 지표로 이제 수익율을 비교해 볼 것입니다.
data = info_dataFrame.reset_index(drop = True).copy()
del data["timedelta"]
data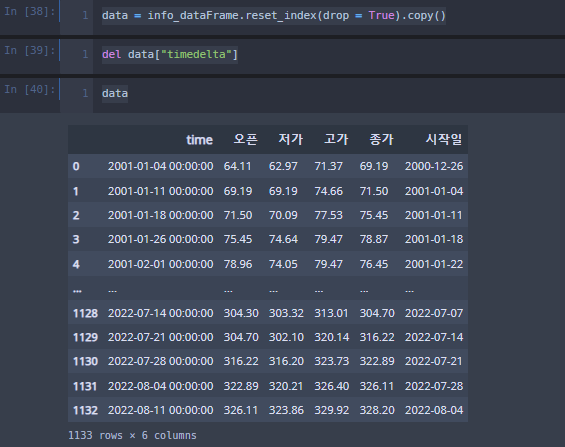
data["단순이동평균_"+"종가"] = SMA(data, period=WINDOW, column='종가')
data["지수이동평균_"+"종가"] = EMA(data, period=WINDOW, column='종가')
data["가중이동평균_"+"종가"] = WMA(data, period=WINDOW, column='종가')
data["최소제곱평균_"+"종가"] = LSMA(data, period=WINDOW, column='종가')
data["삼각이동평균_"+"종가"] = triangular_weighted_moving_average(data, period=WINDOW, column='종가')
unname_list = ["단순이동평균_","지수이동평균_","가중이동평균_","최소제곱평균_","삼각이동평균_"]
val_col_list = set(data.columns)
val_col_list = set(data.columns) - {"시가","고가","저가","종가","날짜","오픈","time","진입시점","시작일"}
val_col_list = set(val_col_list)
val_col_list = list(val_col_list)
data['time'] = pd.to_datetime(data['time'], format='%Y-%m-%d', errors='raise')
# data['시작일'] = pd.to_datetime(data['시작일'], format='%Y-%m-%d', errors='raise')
data = data.fillna(0)다양한 이동평균선을 전략으로 사용해 비교합니다. 이전 주 시가(t -1 시점[수요일]) vs 이번 주 종가(t 시점 [목요일])
for l in unname_list:
name = [s for s in val_col_list if l in s]
if (name[0].find("종가")):
data["종가"+"-"+str(name[0])] = data["종가"] - data[name[0]]
data.loc[list(data.loc[(data[name[0]]==0)][name[0]].index),"종가"+"-"+str(name[0])] = 0 # 원래 0 이였던 값들을 찾은다음 다시 0 을 집어넣어줌.
data.loc[(data["종가"+"-"+str(name[0])])> 0,l+"포지션"] = "상방"
data.loc[(data["종가"+"-"+str(name[0])])< 0,l+"포지션"] = "하방"
data.to_csv(save_path+"ALL_DATA_KOSPI_spot_목종목시.csv", encoding = "cp949")데이터의 종가가 상방인지 하방인지 비교하여 데이터를 저장합니다.
info_2 = {}
for j in tqdm(val_col_list):
col_name = j
info_2[col_name] = []
for i in range(len(data)):
if(data.iloc[i,:][col_name] == "None"):
info_2[col_name].append(None)
else:
new_df = df.loc[df.time.between(data.iloc[i,:].시작일,data.iloc[i,:].time)]
if (new_df.iloc[1,:].오픈 <= data.iloc[i,:][col_name]):
state = "Long"
else: # new_df.iloc[1,:].오픈 >= data.iloc[i,:][col_name])
state = "Short"
# print(state)
if state == "Long":
info_2[col_name].append(data.iloc[i,:][col_name] <= max(new_df.고가))
# print(data.iloc[i,:][col_name] , max(new_df.고가))
elif state == "Short":
info_2[col_name].append(data.iloc[i,:][col_name] >= min(new_df.저가))
# print(data.iloc[i,:][col_name] , min(new_df.저가))
info_2 = pd.DataFrame(info_2)
for j in val_col_list:
print(j)
print("총 날짜",len(info_2[(info_2[j] == True) | (info_2[j] == False)][j]))
print("맞은 날짜",sum((info_2[(info_2[j] == True) | (info_2[j] == False)][j])))
print("정답률",sum((info_2[(info_2[j] == True) | (info_2[j] == False)][j]))/len(info_2[(info_2[j] == True) | (info_2[j] == False)][j]))
print("=====================================================================")t시점의 종가{=목요일 시가 [ =만기일 만기시점(목요일 시작)]}보다 지표가 위에 있으면 숏 반대의 경우(지표가 아래에 있으면) 롱 포지션 낮으면 숏포지션이라고 예측합니다.
t시점인 목요일 종가 즉.옵션 만기가 되는 시점에 롱 포지션 이 맞는 경우 True, 숏 포지션이 맞을경우 True를 반환합니다.
그렇게 하여 정답율을 비교해본 결과입니다.

해당 내용은 깃허브에 기재하겠습니다
'IT - 코딩 > 트레이딩 관련' 카테고리의 다른 글
| 갭상, 갭락 자동 알람기 (전부 무료, 코드 수정가능 (코드전체 공개)) 구글 서버가 24시간 실행해줌. (6) | 2025.07.11 |
|---|---|
| 환전소 금액 1초마다 크로링 (1) | 2023.05.22 |
| 1배숏을 응용한 차익거래 프로그램(주요 이슈 및 해결 방안) (1) | 2023.02.28 |
| 통계적 차익거래를 위한 데이터 분석 및 머신러닝 활용방안 (0) | 2023.02.27 |
| 무위험 차익거래 자동매매 프로그램 2.주요 이슈와 해결 내용. (0) | 2023.02.26 |


