import openai
import time
messages = []
out_put = []
err_list = []
openai.api_key = "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" # api 키는 https://platform.openai.com/overview 여기에서 발급받기 바랍니다###############보미 사전학습 모델 (시작) ##################
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizerFast, BertForSequenceClassification, AdamW
from sklearn.model_selection import train_test_split
import pandas as pd
# Load dataset
df = combined_df
# Split into training and testing
train_texts, test_texts, train_labels, test_labels = train_test_split(df['review'], df['label'], test_size=0.2)
# Load pre-trained tokenizer
tokenizer = BertTokenizerFast.from_pretrained('beomi/kcbert-base')
# Tokenize the texts
train_encodings = tokenizer(list(train_texts), truncation=True, padding=True, max_length=256)
test_encodings = tokenizer(list(test_texts), truncation=True, padding=True, max_length=256)
class KoreanTextDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)데이터를 불러와서 파이토치를 사용하여 트레인셋과 테스트 셋을 나눕니다.
토큰나이저는 보미셋을 이용할 것이니 코버트 베이스의 보미 셋 토크나이저를 이용합니다.
# Convert to PyTorch Dataset
train_dataset = KoreanTextDataset(train_encodings, list(train_labels))
test_dataset = KoreanTextDataset(test_encodings, list(test_labels))
# Load pre-trained model
model = BertForSequenceClassification.from_pretrained('beomi/kcbert-base', num_labels=2)
# Set up training parameters
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.train()
optimizer = AdamW(model.parameters(), lr=1e-5)한국어 데이터 셋을 변환하고, 허깅페이스에 기재되어 있을 한국어 코버트 보미셋을 이용합니다.
긍부정 판단이니 라벨은 2개로 해줍시다.
저는 지금 컴퓨터에 gpu사용을 다시 깔아야 하는 시점인데 해당 코딩을 빠르게 짜서 도와줘야 하는 입장이라 돌리고 잣습니다.. ㅎㅎ
그리고 요즘 좋다는 아담 w사용해주었습니다.
from tqdm import tqdm
from sklearn.metrics import accuracy_score
# Training
model.train()
for epoch in tqdm(range(5), desc='Epochs'): # number of epochs
loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
for batch in tqdm(loader, desc='Training'):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
학습언제 다 될지.. 학습해주고
from tqdm import tqdm
import numpy as np
# Switch model to evaluation mode
model.eval()
# DataLoader for our evaluation set
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)
# Variable to gather all predictions
predictions = []
all_logits = []
# Evaluate data for one epoch
for batch in tqdm(test_loader, desc='Predicting'):
with torch.no_grad():
# Forward pass
outputs = model(**{k: v.to(device) for k, v in batch.items()})
# Get the logits from the model output
logits = outputs.logits
# Get the predicted class for each example in the batch (the class with the highest probability)
_, predicted = torch.max(outputs.logits, 1)
# Move predictions to CPU and convert to NumPy array
predicted = predicted.cpu().numpy()
logits = logits.cpu().numpy()
# Append batch predictions
predictions.extend(predicted)
all_logits.extend(logits)
# Convert list to a numpy array for further processing or analysis
predictions = np.array(predictions)
all_logits = np.array(all_logits)테스트 셋 학습해서 붙여줍니다.
torch.save(model, f'./beomi.pt')
모델은 다시 돌리면 오래걸리니 저장은 필수!
###############보미 사전학습 모델 (끝) ################
import pandas as pd
import os
from tqdm import tqdm
path = os.getcwd() # 주피터 노트북 파일 경로
# os_file_list = os.listdir(path) # 내 경로 읽어서 파일 리스트 읽음
data_frame_samsung = pd.read_excel(path+"\\"+"samsung_laptop2.xlsx")
data_frame_lg = pd.read_excel(path+"\\"+"lg_laptop2.xlsx")
data_frame_apple = pd.read_excel(path +"\\"+"apple_laptop2.xlsx")
combined_df = pd.concat([data_frame_samsung, data_frame_lg, data_frame_apple], ignore_index=True) # 데이터 한번에 결합.
먼저 이러한 데이터 셋이 있고
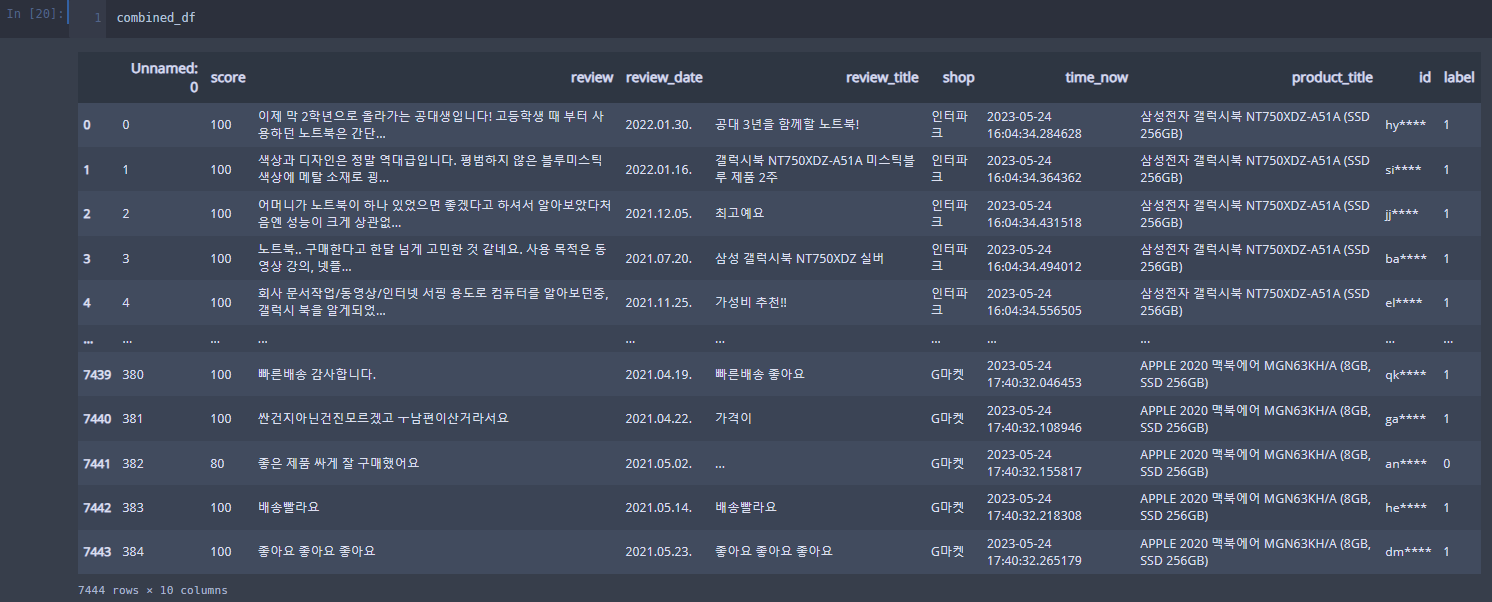
챗 gpt api를 이용해 긍부정을 판단해달라고 합시다.
import openai
import time
messages = []
out_put = []
err_list = []
openai.api_key = "sk-9jFuoRm458458Q458l458pe4588qy6458mIbzoWW" # api 키는 https://platform.openai.com/overview 여기에서 발급받기 바랍니다for i in range(len(combined_df["review"])):
try:
user_content = "다음 문장이 긍정이면 1 부정이면 0으로 대답해줘 "+"''"+combined_df["review"][i]+"''"
messages.append({"role": "user", "content": f"{user_content}"})
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages)
assistant_content = completion.choices[0].message["content"].strip()
messages.append({"role": "assistant", "content": f"{assistant_content}"})
# print(assistant_content)
if "1" in assistant_content:
out_put.append((i,1))
else:
out_put.append((i,0))
messages = []
print(i,out_put[-1])
except Exception as e:
err_list.append(i) # 에러 난 부분 i값
print("예외가 발생했습니다",e) # 서버 오류로 가끔 예외 발생
passgpt보고 긍정이면 1 부정이면 0으로 대답하라고 명령했습니다. 하지만 긍정(1) 이런식으로 대답하길래 어떤 숫자를 텍스트에 포함하고 있는지에 따라 판단하게 하였습니다.(ex 0 을 포함하는 텍스트 이면 부정)
또 문제가 발생하는 부분이 리스트 식으로 계속해서 1개씩 물어보는데 서버에서 api request요청에 대한 답이 오류가 날 때(서버가 이상할 때)가 존재 하였습니다. 그런 데이들은 우선 넘어가고 예외가 발생한 인덱스를 err_list에 저장합니다.
combined_df["out_put"] = "예외"
for i,v in enumerate(out_put):
combined_df["out_put"][v[0]] = v[1] # 긍부정 판단 값을 데이터 프레임에 저장, 예외가 발생하였기 때문에 for문을 사용함err_list_2 = list(combined_df.loc[combined_df["out_put"] == "예외"].index)
combined_df["out_put"][err_list_2[i]] # 에러 인덱스 출력# 에러가 나왔던 부분들만 다시 검산
err_list_3 = []
for i in range(len(err_list_2)):
try:
user_content = "다음 문장이 긍정이면 1 부정이면 0으로 대답해줘 "+"''"+combined_df["review"][err_list_2[i]]+"''"
print(user_content)
messages.append({"role": "user", "content": f"{user_content}"})
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages)
assistant_content = completion.choices[0].message["content"].strip()
messages.append({"role": "assistant", "content": f"{assistant_content}"})
print(assistant_content)
if "1" in assistant_content:
combined_df["out_put"][err_list_2[i]] = 1
else:
combined_df["out_put"][err_list_2[i]] = 0
messages = []
print(err_list_2[i],out_put[-1])
except Exception as e:
err_list_3.append(i) # 에러 난 부분 i값
print("예외가 발생했습니다",e)
pass
에러가 발생한 부분만 다시 검산하는 부분입니다. 에러가 난 컬럼들만 긍부정을 재판단 합니다. 참고로 에러가 날 수 있는 컬럼중에서 gpt의 input 토큰 한계를 넘어서면 대답을 하지 못합니다.
combined_df.loc[combined_df["out_put"]== 0]
으로 확인해보면
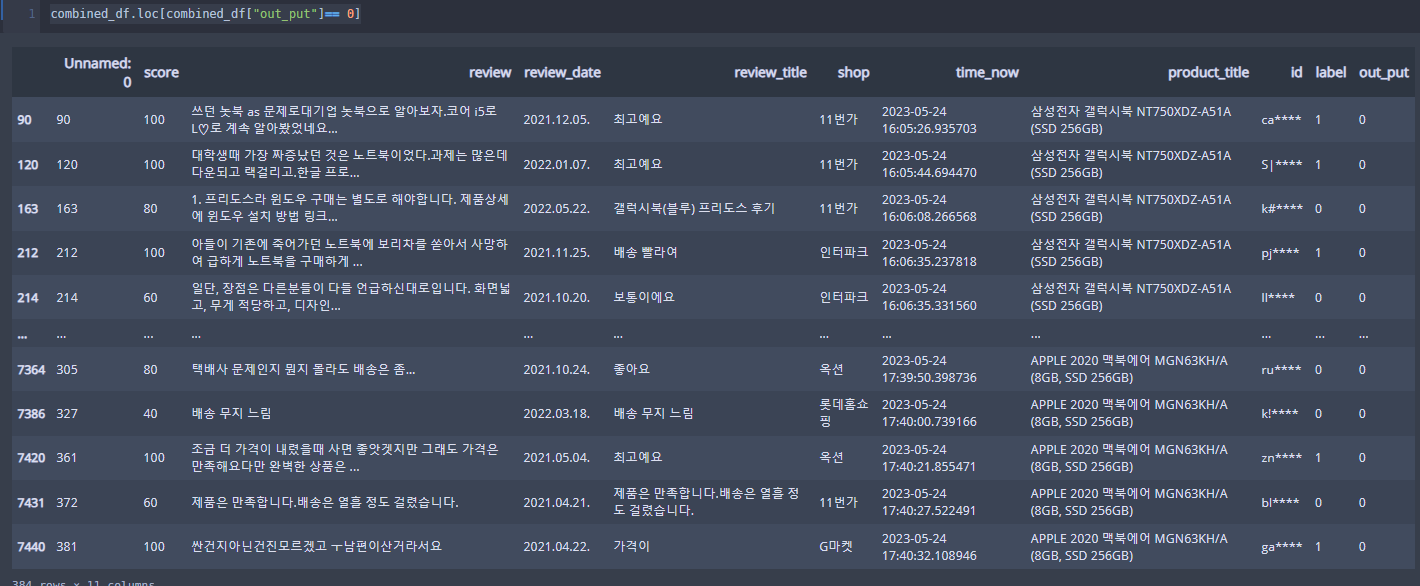
gpt의 아웃풋을 보면 라벨 보다 훨씬 좋네요,.라벨은 다른 모델이 판단한 부분입니다. 해당 부분모다 gpt의 성능이 훨씬 뛰어나네요.
반면에 라벨이 부정(0)이라고 판단한 부분을 보면 긍정인 리뷰가 많습니다. 아웃풋 을 확인하면 보미 모델은 문제가 많습니다.
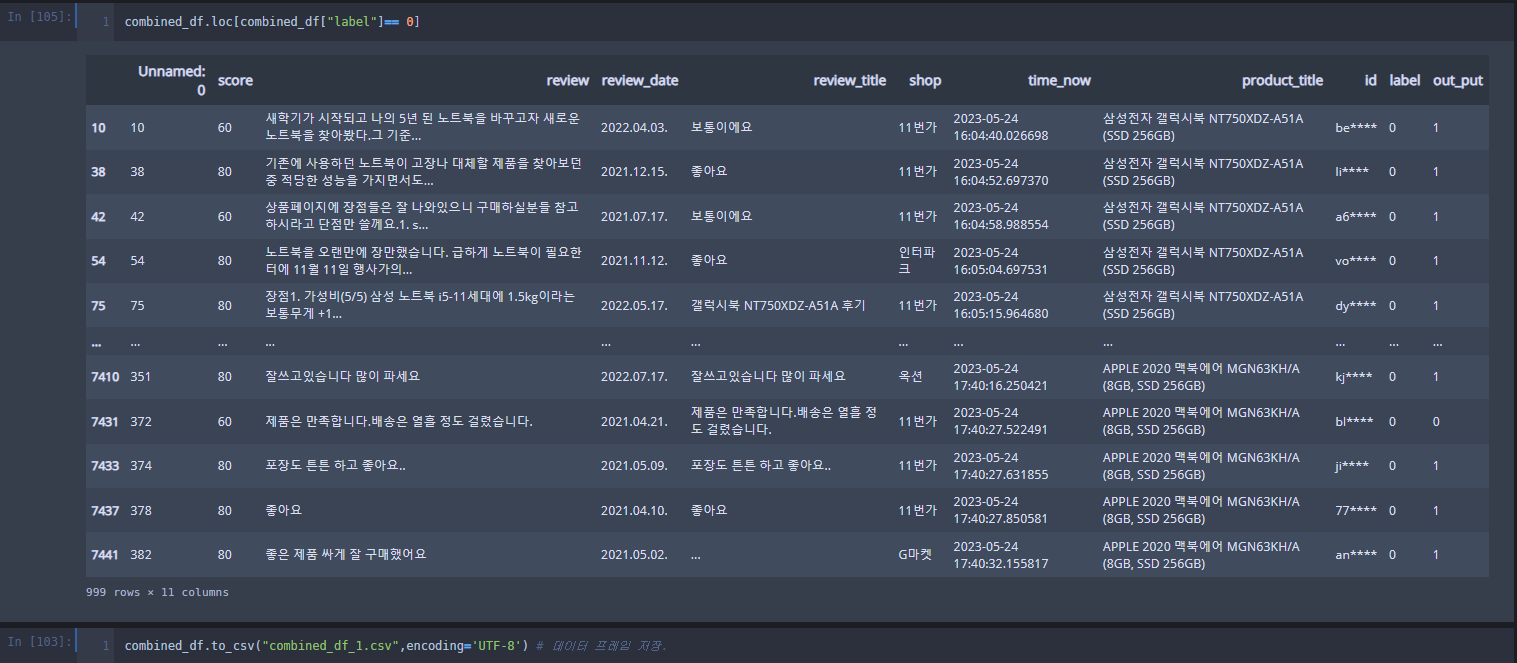
gpt와 보미 모델을 비교해봅시다.
이렇게 되네요..
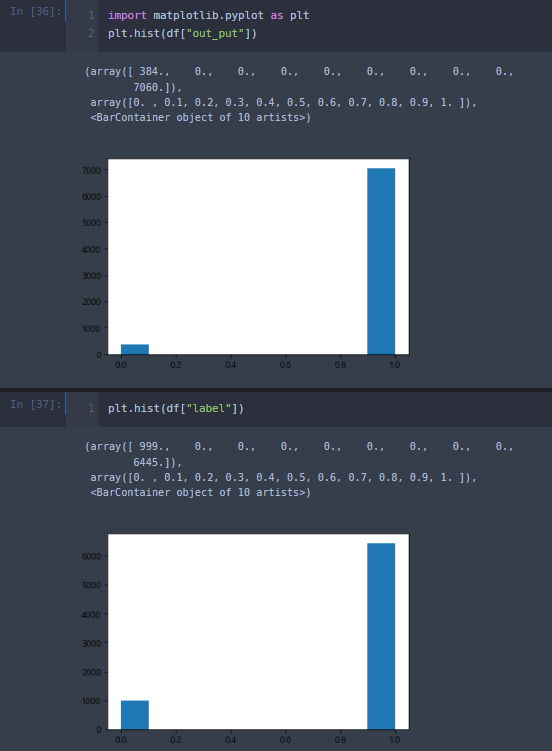
라벨을 확인해 보면 이렇습니다 깃허브에 기재해 둘 테니 더 비교해 보셔두 됩니다.
'IT - 코딩 > AI, 예측모델' 카테고리의 다른 글
| [데이콘]데이크루 6 _ 신용카드 연체 예측 (0) | 2023.09.17 |
|---|---|
| 전력 사용량 예측 (0) | 2023.08.07 |
| 자연어 처리 _ 키워드 추출 key bert ) with python & pytorch (3) | 2023.01.03 |
| 자연어 처리 _ 구문 속 질의응답 모델(QA) with python & pytorch (코랩 pro 사용) (0) | 2023.01.03 |
| 자연어처리 긍부정 판단 with python & pytorch (bert) (2) | 2022.11.19 |

